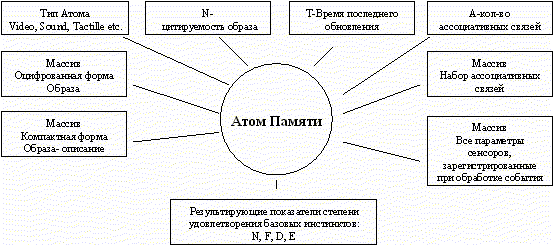
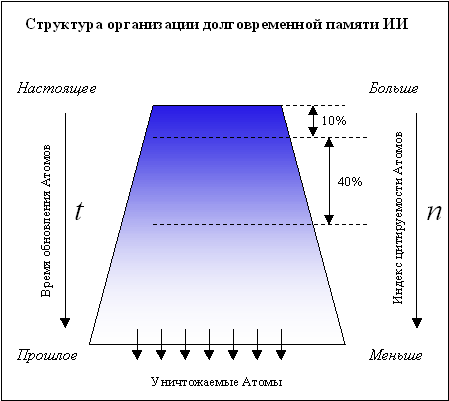
|

Artificial Intelligence - Искусственный Интеллект... мы тоже работаем над этим!
-
На этой странице я поделюсь опытом и размышлениями о проблеме создания Искусственного Интеллекта (ИИ), причем не только в оригинальной теории, но я в практических применениях.
Не думаю, что БОЛЬШИМ специаистам в этой области будет интересен раздел, т.к. тут будет представлены МОИ личные рассуждения, свои "открытия" и находки, которые возможно уже открыты и найдены ранее большими академическими умами. Тем более интересно взглянуть на идею по-новому, под другим углом зрения.
|
|
 А толчок к началу размышлений и практических выводов о разработке собственной модели ИИ послужило крайне малое на сегодня предложение устройств с применением ИИ на массовом рынке. Удивительно, что при повальной компьютеризации, наличию "умных" высокопроизводительных PDA, сотовых телефонов, программируемых телевизоров и микроволновых печей, изделий типа SONY-вской собачки AIBO крайне мало! И это в нашем продвинутом 21 веке!
А толчок к началу размышлений и практических выводов о разработке собственной модели ИИ послужило крайне малое на сегодня предложение устройств с применением ИИ на массовом рынке. Удивительно, что при повальной компьютеризации, наличию "умных" высокопроизводительных PDA, сотовых телефонов, программируемых телевизоров и микроволновых печей, изделий типа SONY-вской собачки AIBO крайне мало! И это в нашем продвинутом 21 веке! Даже прочитав последние дайджесты НАСА о марсоходах, недавно стартовавшихк красной планете, я понял, что и тут-то все также обстоит примитивно. По-существу, это те же радиоуправляемые модели, задача которых только и состоит в том, чтобы не натыкаться на камни в моменты радиомолчания с Земли! Правда, с технической точки зрения, шасси марсохода выполненно на 5!
Даже прочитав последние дайджесты НАСА о марсоходах, недавно стартовавшихк красной планете, я понял, что и тут-то все также обстоит примитивно. По-существу, это те же радиоуправляемые модели, задача которых только и состоит в том, чтобы не натыкаться на камни в моменты радиомолчания с Земли! Правда, с технической точки зрения, шасси марсохода выполненно на 5!